[Review] RESTAD : REconstruction and Similarity based Transformer for Anomaly Detection
Ghorbani, R., Reinders, M. J. T., & Tax, D. M. J. (2024). RESTAD: REconstruction and Similarity based Transformer for time series Anomaly Detection. Manuscript under review. arXiv:2405.07509.
최신 논문 중 나랑 비슷한 고민 중인 논문을 발견해서, 간단히 모델 변경 없이 Transformer 모델에 적용해 볼 수 있을 것 같아 리뷰해보기로 하였다! 논문도 짧고 이런 방법론 너무 재밌자나💫😫 이 방법이 도움이 될지는 사용해봐야 알겠지만,,
Contents
1. Introduction
Limitations of Previous Research
- 재구성 오류 기반 접근의 한계: 기존 비지도 학습 방식은 재구성 오류에 의존함. 이로 인해 복잡한 데이터셋에서 미세한 이상치를 탐지하는 데 어려움이 있음. 모델이 정상 패턴을 잘 학습할 경우, 미묘한 이상치도 정상으로 잘못 재구성되는 문제가 발생함.
- 과도한 일반화 문제: 모델이 훈련 데이터의 주요 패턴을 지나치게 일반화하면서 미묘한 이상치를 정상 데이터로 간주하는 경향이 있음. 이로 인해 이상치 탐지 민감도가 저하됨.
- 과소 탐지 문제: 재구성 오류만을 기준으로 이상치를 탐지할 때, 미세한 이상치는 탐지 임계값 이하로 남아 탐지되지 않을 가능성이 있음.
- 보완 방법의 한계: 'association discrepancy' 기법과 같은 보완 방법이 존재하지만, 정상 데이터에도 과도하게 높은 이상치 점수를 부여해 정상적인 데이터가 잘못된 이상치로 분류될 위험이 있음.
- 데이터의 고차원성과 복잡성: 기존 모델들이 고차원적이고 복잡한 시계열 데이터의 시간적 의존성을 효과적으로 처리하지 못함.
RESTAD: REconstruction and Similarity based Transformer for Time Series Anomaly Detection
- Transformer 기반 아키텍처: RESTAD는 시계열 데이터를 처리하기 위해 Transformer 모델을 기반으로 설계됨. 이 아키텍처는 시계열 데이터의 시간적 의존성을 효과적으로 포착하는 데 뛰어남.
- RBF 레이어 추가: RESTAD의 주요 개선점은 Transformer 구조에 Radial Basis Function (RBF) 뉴런을 추가한 것임. RBF 뉴런은 데이터 포인트와 학습된 기준점들 간의 유사도를 측정하여 일반적인 데이터와 이상 데이터를 구별하는 데 사용됨. RBF 유사도 점수를 통해 데이터 포인트가 학습된 기준점과 얼마나 가까운지를 측정하며, 거리가 멀수록 이상치로 간주됨.
- 복합 이상치 점수: RESTAD는 RBF 유사도 점수와 재구성 오류를 결합하여 복합 이상치 점수를 계산함. 이 복합 점수를 통해 미세한 이상치와 중요한 이상치를 모두 효과적으로 탐지할 수 있음.

2.Model
RBF Layer : 데이터와 기준점간의 거리 기반 유사도를 계산
1.Input
RESTAD 모델에서는 RBF(Radial Basis Function) 레이어를 Transformer 모델의 일부로 통합하여 이상 탐지를 수행.
RBF 레이어는 이전 레이어인 Transformer의 인코더에서 출력된 Latent representation을 입력으로 받음.
2.유사도 계산
각 데이터 포인트(hi,t)와 기준점(cm )사이의 거리를 측정하고, 그 거리에 따라 유사도 점수를 계산.

--> 거리가 가까울수록 유사도 점수가 증가, 거리가 멀수록 유사도 점수가 감소.
(폭이 넓다는 것은 멀리 떨어진 데이터 포인트들도 어느 정도의 유사도를 가질 수 있다는 것을 의미하여 유사도 점수가 크게 떨어지지 않게 됨.)
γ 파라미터는 학습 중에 조정되며, 학습 과정에서 γ를 조정하면서 최적의 폭을 찾음.

Anomaly Score
복합적으로 이상치 점수를 계산하여 이상치를 더 명확하게 구별할 수 있도록 함.
RBF 유사도 점수 (𝜖_𝑠):
각 데이터 포인트가 학습된 기준점들에 얼마나 가까운지를 측정.
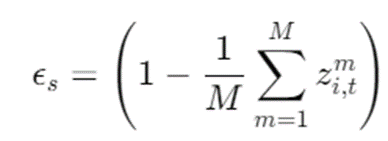
재구성 오류 (𝜖_r):
실제 데이터와 재구성된 데이터 간의 제곱 차이(평균 제곱 오차(MSE))로 계산됩니다.
--> 높은 재구성 오류는 데이터가 이상치일 가능성이 높다는 것.
RESTAD 이상 점수:

이 점수는 낮은 재구성 오류와 낮은 RBF 점수를 가진 미세한 이상치와 높은 재구성 오류나 낮은 RBF 점수를 가진 큰 이상치를 모두 효과적으로 탐지 가능.
Initialization of RBF Layer Parameters
RBF 레이어의 기준점(centers) c와 스케일 파라미터 𝛾의 초기화는 모델 성능에 중요한 영향을 미침.
1.Random initialization
c와 𝛾를 평균이 0이고 표준편차가 1인 정규분포에서 무작위로 추출.
장점: 단순하고 빠른 초기화 가능.
2.K-means initialization
잠재 표현Latent Representation을 기반으로 K-means clustering 알고리즘을 사용하여 기준점c을 초기화.
𝛾 초기화
데이터 포인트와 가장 가까운 기준점 간의 평균 제곱 거리를 계산


--> γ 값이 클수록 RBF 함수의 폭이 좁아져서 가까운 거리에서 급격히 유사도가 감소.
장점: 데이터 구조를 더 잘 반영하여 초기화하므로, 보다 안정적인 학습 가능.



Model Architecture
Encoder Layer(Transformer 인코더 구조)
* Transformer의 encoder에서 Query(Q)와 Key(K)를 사용하여 attention score를 계산하고, Value(V)와 내적을 통해 Context vector를 출력.
RBF Layer: 데이터 포인트가 사전에 학습된 기준점(클러스터 중심점)과 얼마나 유사한지를 계산
3. Experimental Result
시각적 결과 분석(SMD Dataset)

- PatchAD, DCDetector, AnomalyTrans: 많은 오탐지가 발생하며, 특히 DCDetector는 반복적인 오탐지를 보여줌. PatchAD는 랜덤한 점수를 보이는 경향이 있음.
- LSTM, USAD, Transformer: 일부 이상치 영역을 탐지하지 못하거나, 탐지 강도가 약함. USAD는 첫 번째 이상치 영역을 전혀 탐지하지 못했으며, LSTM과 Transformer는 약하게 탐지함.
- RESTAD: 모든 이상치 영역을 효과적으로 탐지하여, 다른 모델들에 비해 훨씬 더 뛰어난 이상 탐지 성능을 보여줌.
Anomaly Score 계산 방법 비교 및 시각적 결과 분석
𝜖_𝑠 × 𝜖_𝑟 (𝜖_𝑠 : RBF 점수, 𝜖_𝑟: 재구성 오류)로 구성된 복합 이상치 점수 계산이 가장 효과적임을 확인.
단순 재구성 오류(𝜖_𝑟)를 사용하는 경우, 일부 데이터셋에서는 성능이 약간 향상되었지만, 𝜖_𝑠만을 사용하거나 𝜖_𝑠+𝜖_𝑟로 단순 합산한 경우에는 성능이 현저히 떨어짐.
--> 복합 이상 점수 계산 방법은 기존의 재구성 오류 기반 점수보다 미세한 이상치를 더 잘 탐지하는 것을 시각적으로 입증.

RBF Layer 위치 및 기준점 개수 성능 비교

- RBF 레이어 위치에 따른 성능: RBF 레이어의 위치에 관계없이 성능이 견고하게 유지됨. 두 번째 인코더 레이어 뒤에 배치했을 때 성능이 약간 더 향상되는 경향이 있음.
- RBF 기준점 수에 따른 성능: RBF 레이어의 기준점 수는 데이터에 따라 최적의 값이 달라짐. 기준점이 너무 많으면 오히려 성능이 저하될 수 있음.
Conclusion
- RESTAD의 개선점: RESTAD는 Transformer 모델에 RBF 계층을 통합하여 기존 재구성 오류 기반 이상 탐지의 한계를 극복함.
- 복합 점수 도입: 유사도 점수와 재구성 오류를 결합한 복합 점수를 통해 이상치 탐지 성능을 향상시킴.
- 우수한 성능: RESTAD는 다양한 데이터셋과 평가 지표에서 기존 모델들을 능가하는 뛰어난 성능을 보여줌.
- RBF 센터 수 조정: 최적의 RBF 센터 수는 데이터셋에 따라 다르며, 데이터 특성에 맞게 조정이 필요함.
아직 게재되지 않은 논문을 리뷰해보았다 😶🌫️ 좀 간단한 방법이지만 이 사람들도 나랑 같은 고민을 하고... 생각한 최선의 방법이었을 수도.. 있겠다는 생각이.. 🤣 성능 높이기 쉽지 않다 ~~ 화이팅 😎