해당 내용은 Laurence Moroney 교수님의 Coursera의 TensorFlow Developer Professional Certificate의 2주차 강의 A New Programming Paradigm를 듣고 정리한 내용이다.
강의를 미루지 말자!!!
An Introduction to computer vision
Fashion MNIST 데이터 세트를 사용하여 신발, 셔츠, 핸드백 등의 패턴을 컴퓨터에 학습시키는 방법을 배울 예정임.
이 데이터 세트는 70,000개의 이미지로 구성되어 있으며, 각 이미지는 28x28 픽셀의 흑백 이미지임.
이를 통해 신경망을 훈련시키고 이미지 내에 있는 물체를 인식할 수 있길...
Writing code to load training data

텐서플로에 fashion mnist datasets가 존재함.
불러서 사용
Coding a Computer Vision Neural Network

첫 번째 레이어 : 훈련 img의 w,h
중간 레이어: 연산을 위한 히든 레이
마지막 레이어 : 클래스
flatten : 2차원 배열을 단순 1차원 배열로 변경


앤드류씨의 아주 자세한 수학적 내용이 담긴 유튭 강의. 나중에 봐야지
Walk through a Notebook for computer vision
이 페이지에서는 TensorFlow를 사용하여 기본적인 컴퓨터 비전 기능을 제공하는 신경망을 만드는 방법을 배움.
주요 내용은 다음과 같습니다:
- TensorFlow를 가져와서 시작합니다.
- tf.keras.datasets를 사용하여 패션 MNIST 데이터를 가져옵니다.


- 데이터는 0에서 255까지의 픽셀 그레이스케일 값으로 구성된 그리드입니다.

- matplotlib을 사용하여 이미지를 플롯하고 원시 값도 출력할 수 있습니다.

- 데이터를 0과 1 사이로 정규화합니다.

- 모델을 설계하고 컴파일합니다.
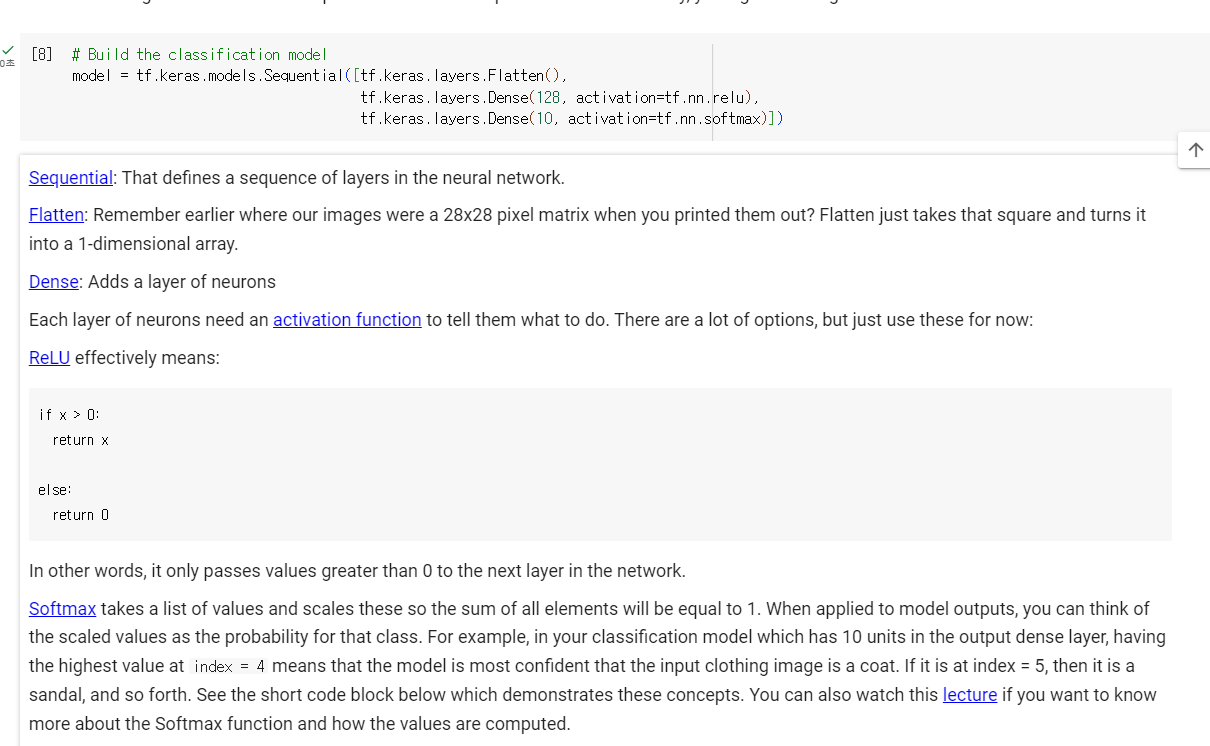
| Sequential: 그것은 신경망의 일련의 레이어를 정의합니다. flatten: 우리의 이미지를 출력할 때 28x28 픽셀 매트릭스가 어디에 있었는지 이전에 기억하십니까? 평면화는 그 정사각형을 가져와서 1차원 배열로 바꿉니다. dense: 뉴런층을 추가합니다 뉴런들의 각 층은 그들에게 무엇을 해야 하는지 알려주는 활성화 기능을 필요로 합니다. 여러 가지 옵션이 있지만, 지금은 이것들을 사용하세요: ReLU : 위의 공식을 의미합니다: 즉, 0보다 큰 값만 네트워크의 다음 계층에 전달합니다. softmax: 클래스별 확률인데 제일 큰 값이 1 이라고 보면될 듯 Softmax는 모든 요소의 합이 1이 되도록 값의 목록을 만들고 이를 척도로 조정합니다. 모형 출력에 적용할 때 척도로 조정한 값을 해당 클래스의 확률로 생각할 수 있습니다. 예를 들어 출력 밀도 계층에 10개 단위가 있는 분류 모형에서 인덱스 = 4에서 가장 높은 값을 갖는 것은 모형이 입력된 의류 이미지를 외투라고 가장 확신한다는 것을 의미합니다. 인덱스 = 5이면 샌들 등입니다. |
- 훈련 이미지를 훈련 레이블에 맞추려고 시도합니다.
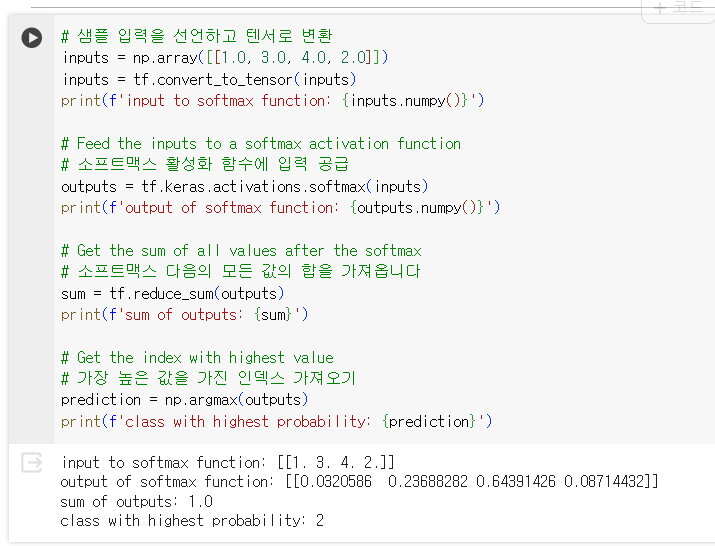

- 테스트 데이터를 사용하여 모델의 성능을 평가합니다.
하지만 눈에 보이지 않는 데이터에서는 어떻게 작동할까요? 그래서 테스트 이미지와 레이블을 가지고 있습니다. 이 테스트 데이터 세트를 입력으로 model.evaluate()라고 부르면 모델의 손실과 정확도가 다시 보고됩니다.

- 목표는 훈련 데이터에서 0.71의 정확도와 테스트 데이터에서 0.66의 정확도를 달성하는 것입니다.
ex

| 연습 1: 이 첫 번째 연습에서는 다음 코드를 실행합니다. 테스트 이미지 각각에 대한 분류 집합을 만든 다음 분류의 첫 번째 항목을 인쇄합니다. 출력은 실행한 후 숫자 목록입니다. 왜 이것이 있다고 생각하고 그 숫자들은 무엇을 나타내는 것이라고 생각하나요? 힌트: 인쇄(test_labels[0])를 실행해 보면 9가 나옵니다. 왜 이 목록이 그렇게 보이는지 이해하는 데 도움이 되나요? E1Q1: 이 목록은 무엇을 나타내는가? 10개의 의미 없는 임의의 값입니다 컴퓨터가 처음으로 만든 10가지 분류입니다 이 항목은 각각 10개의 클래스일 가능성이 있습니다 정답: 정답은 (3)입니다 이 모델의 출력은 10개의 숫자 목록입니다. 이 숫자들은 분류되는 값이 해당 값일 확률입니다. 즉, 목록의 첫 번째 값은 이미지가 '0'(티셔츠/상의)일 확률이고, 다음 값은 '1'(트루저) 등일 확률입니다. 이 숫자들은 모두 매우 낮은 확률이라는 것을 주목하세요. 인덱스 9(Ankle boot)의 경우 확률이 90년대였습니다. 즉, 신경망은 이미지가 발목 부츠일 가능성이 높다고 알려줍니다. |
| E2Q1: 1024개의 뉴런으로 증가 -- 어떤 영향을 미칩니까? 교육은 더 오래 걸리지만 더 정확합니다 교육 시간은 더 걸리지만 정확도에는 영향을 미치지 않습니다 교육은 같은 시간이 걸리지만 더 정확합니다 답변을 클릭합니다 정답. 정답은 (1) 뉴런을 더 추가함으로써 더 많은 계산을 해야 하고, 처리 속도가 느려지지만, 이 경우에는 더 정확해지는 좋은 영향을 미칩니다. 그것은 항상 '더 많이 사용하는 것이 더 좋다'는 것을 의미하는 것이 아니라, 수익 감소의 법칙을 매우 빨리 적용할 수 있습니다! |
| E3Q1: Flatter() 레이어를 제거하면 어떻게 될까요? 왜 그렇다고 생각하세요? 정답. 데이터 모양에 오류가 발생합니다. 지금은 모호해 보일 수 있지만 네트워크의 첫 번째 레이어가 데이터와 동일한 모양이어야 한다는 경험의 법칙이 강화됩니다. 지금 우리 데이터는 28x28 이미지이고 28개 뉴런의 28개 레이어는 실행 불가능하므로 28,28을 784x1로 '평탄화'하는 것이 더 합리적입니다. 우리는 그것을 처리하기 위해 모든 코드를 작성하는 대신 처음에 Flature() 레이어를 추가하고 나중에 어레이가 모델에 로드되면 자동으로 우리를 위해 평탄화됩니다. |

| 연습 4: 최종 출력 레이어를 생각해 보세요. 왜 그것들이 10개일까요? 만약 여러분이 10개와 다른 양을 가진다면 어떻게 될까요? 예를 들어, 5개로 네트워크를 훈련시켜 보세요. 답변을 클릭합니다 정답. 예상치 못한 값을 찾자마자 오류가 발생합니다. 또 다른 경험 법칙은 마지막 층의 뉴런 수가 분류하는 클래스의 수와 일치해야 한다는 것입니다. 이 경우 숫자 0-9이므로 그 중 10개가 있으므로 마지막 층에 10개의 뉴런이 있어야 합니다. |

| 연습 5: 네트워크에서 추가 계층의 효과를 생각해 보세요. 512가 있는 계층과 10이 있는 최종 계층 사이에 다른 계층을 추가하면 어떻게 될까요. 답변을 클릭합니다 정답. 이것은 비교적 간단한 데이터이기 때문에 큰 영향을 미치지 않습니다. 훨씬 더 복잡한 데이터(다음 시간에 볼 꽃으로 분류할 컬러 이미지 포함)를 위해서는 추가 레이어가 필요한 경우가 많습니다. |

| 연습 6: E6Q1: 어느 정도 시대를 위한 훈련의 영향을 고려해 보십시오. 왜 그럴 것이라고 생각하십니까? 15개의 에포크를 시도해 보십시오. 손실이 5개인 모델보다 훨씬 더 좋은 모델을 얻을 수 있을 것입니다 30개의 에포크를 시도해 보세요. 손실 값이 더 천천히 감소하고 때로는 증가하는 것을 볼 수 있습니다. model.evaluate()의 결과가 크게 개선되지 않은 것도 볼 수 있습니다. 심지어 약간 더 나빠질 수도 있습니다. 이것은 나중에 알게 될 '오버피팅'이라는 것의 부작용으로 신경망 훈련을 할 때 주의해야 할 부분입니다. 손실이 개선되지 않는다면 훈련하는 데 시간을 낭비하는 것은 의미가 없지 않나요? :) |
| 연습 7: 훈련하기 전에 0-255 값에서 0-1 값으로 데이터를 정규화했습니다. 이를 제거하면 어떤 영향을 받을까요? 여기 시도해 볼 수 있는 전체 코드가 있습니다. 왜 다른 결과를 얻을 수 있다고 생각하나요? |
| 연습 8: 이전에 추가적인 에포크를 위해 훈련했을 때 손실이 변경될 수 있는 문제가 있었습니다. 훈련이 완료될 때까지 기다리시는 데 시간이 좀 걸릴 수도 있고, '원하는 값에 도달하면 훈련을 중단할 수 있으면 좋지 않을까'라고 생각하셨을 수도 있습니다. 즉, 60%의 정확도가 당신에게 충분할 수도 있고, 3번 에포크 후에 그 값에 도달하면 훨씬 더 많은 에포크가 끝날 때까지 앉아서 기다리는 것은 어떨까요? 그렇다면 어떻게 고칠 것인가요? 다른 프로그램처럼... 콜백이 있습니다! 그들이 실전에 있는 것을 봅시다... |
| 8번 code |
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy') >= 0.6): # Experiment with changing this value
print("\nReached 60% accuracy so cancelling training!")
self.model.stop_training = True
callbacks = myCallback()
fmnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels) , (test_images, test_labels) = fmnist.load_data()
training_images=training_images/255.0
test_images=test_images/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5, callbacks=[callbacks])
Using Callbacks to control training

손실값이 0.4보다 작으면 종료


------
Week 2: Implementing Callbacks in TensorFlow using the MNIST Dataset
| 2주차: MNIST 데이터셋을 이용한 TensorFlow에서의 콜백 구현 이 과정에서 여러분은 패션 MNIST를 사용하여 분류하는 방법을 배웠습니다. MNIST라고 불리는 또 다른 유사한 데이터 세트는 손글씨를 포함합니다. 0에서 9까지의 숫자입니다. 99%의 정확도로 훈련되고 이 임계값이 달성되면 중지되는 MNIST 분류기를 작성하십시오. 강의에서 손실을 위해 이것이 어떻게 이루어졌는지 보았지만 여기서는 정확도를 대신 사용하게 됩니다. 일부 참고 사항: 네트워크는 9개 미만의 에포크에서 성공해야 합니다. 99% 이상이 되면 "99%의 정확도에 도달하여 훈련을 취소합니다!"라는 문자열을 출력하고 훈련을 중단해야 합니다. 변수를 추가할 경우 클래스에서 사용한 이름과 동일한 이름을 사용해야 합니다. 이는 콜백의 함수 서명(파라미터 및 이름)에 중요합니다. |
조건
- 9에폭 미만에서 정확도 99%이상 9epoch 이상

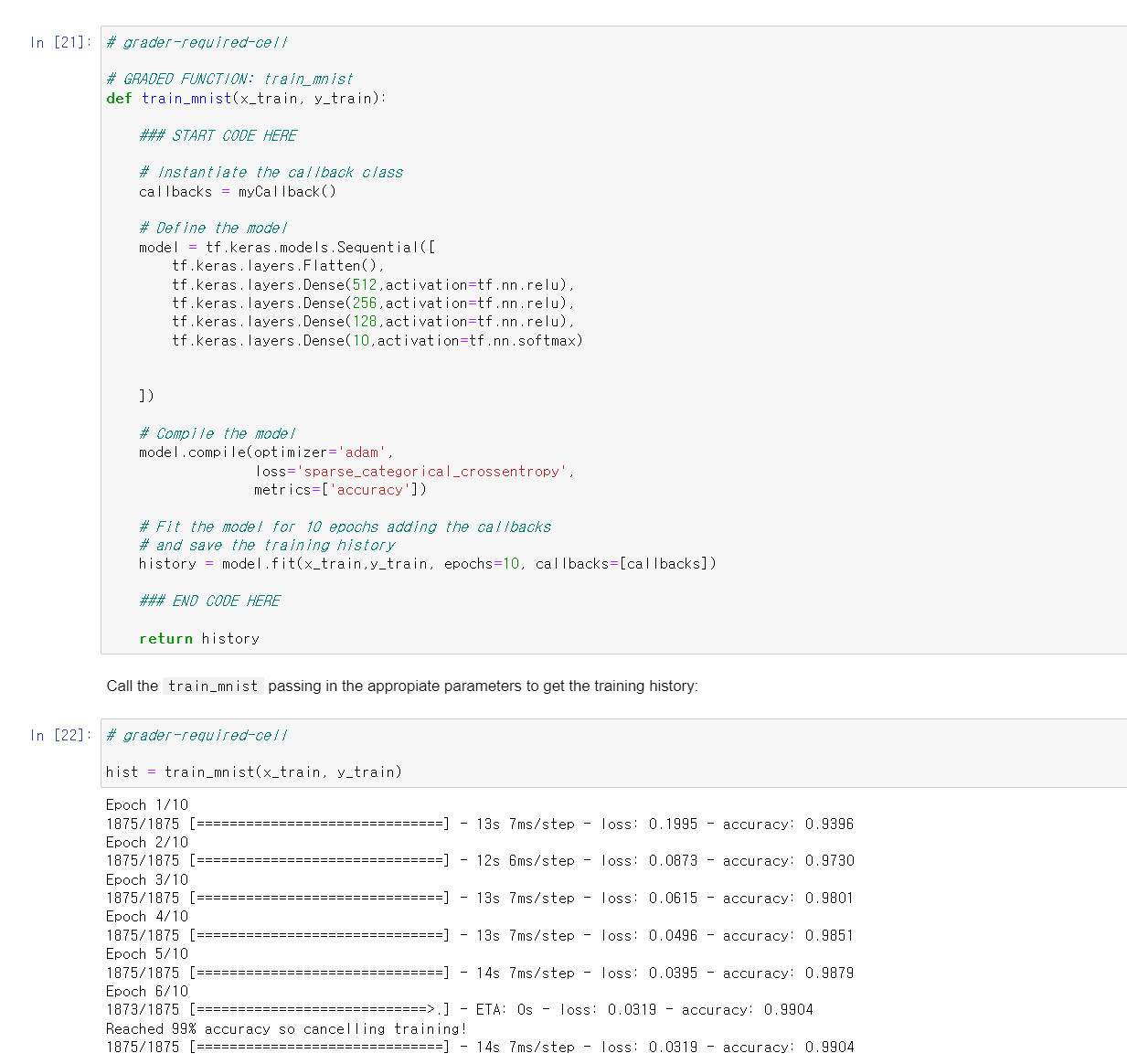
성공~