* Karim, F., Majumdar, S., Darabi, H., & Chen, S. (2018). LSTM Fully Convolutional Networks for Time Series Classification. IEEE Access, 6, 1662-1669.
LSTM Fully Convolutional Networks for Time Series Classification 논문을 리뷰하면서 부족한 이론을 추가 정리하려고 한다.😂
https://ieeexplore.ieee.org/document/8141873
Contents
1. Introduction
Limitations of Previous Research
purpose of study
2.앙상블 알고리즘의 복잡성:
3.과도한 하이퍼파라미터 튜닝:
|
2. Model
Proposed Models
Methods for Performance Enhancement
FCN의 성능 향상위해 Temporal Convolutions, LSTM RNN, Attention Mechanism을 결합한 모델 제안
(1). Temporal Convolutions
(2).Recurrent Neural Networks (순환 신경망, RNN)
시간적인 흐름을 갖는 데이터를 처리하는 데 사용되는 신경망 구조
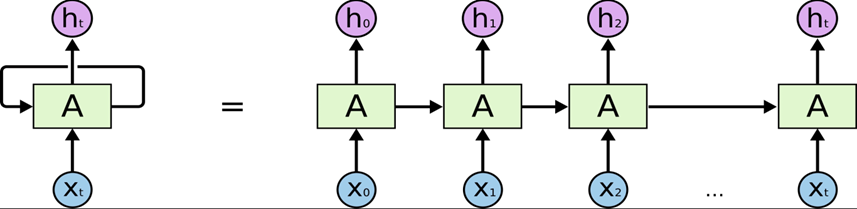
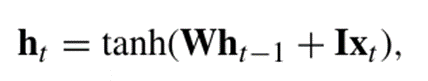
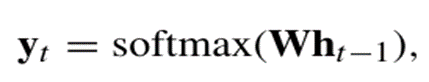
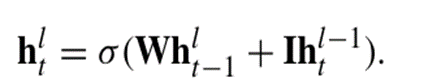
(3). Long Short-Term Memory(LSTM)
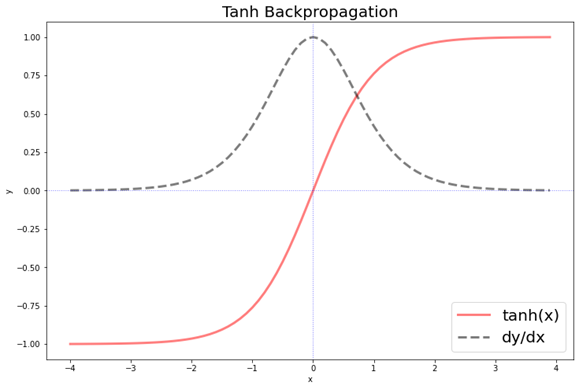
일반적인 RNN에서의 기울기 소실 문제를 해결하기 위해 게이트 기능 추가 --> 장기 의존성 학습에 강점
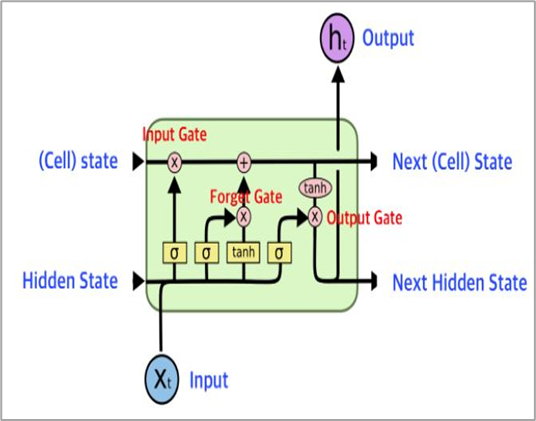
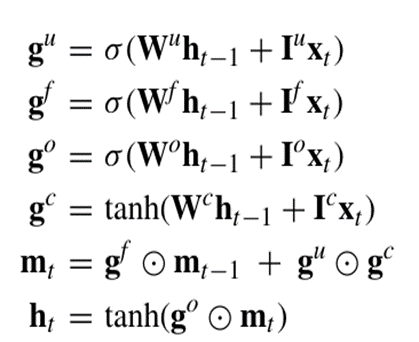
-->LSTM은 일반적인 RNN보다 장기 의존성을 더 잘 학습하지만 긴 시퀀스에서는 장기 의존성 학습에 한계 존재
(4). Attention Mechanism
입력 시퀀스의 중요한 부분에 집중해 긴 시퀀스에서도 장기의존성 문제 해결
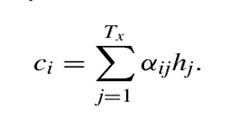
- Ci : 출력 시퀀스의 i번째 위치에서의 Context vector
- hj : 입력 시퀀스의 j번째 위치에서의 hidden state
- Tx : 입력 시퀀스의 길이
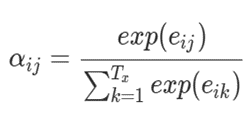
- 가중치 αij : i번째 출력과 j번째 입력 간의 가중치, 각 hj의 중요도 결정
: softmax function사용해 입력 값들을 확률로 변환
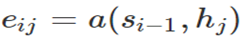
- 정렬 모델 eij : j번째 입력 시퀀스와 i번째 현재 출력간 관련성 측정
- Function a: 작은 신경망(피드포워드 신경망(FFNN))으로 구현, 두 입력 사이의 관련성 계산
- Si-1 : LSTM 이전 출력 시퀀스의 hidden state
Temporal Convolution, LSTM RNN, Attention Mechanism을 결합한 모델
à시계열 데이터의 특징을 효과적으로 추출하고, 긴 시퀀스에서도 중요한 부분에 집중하여 장기 의존성 문제 해결
2-1. Performance Evaluation
CBF 데이터셋에서 Attention LSTM 셀의 context vector 시각화
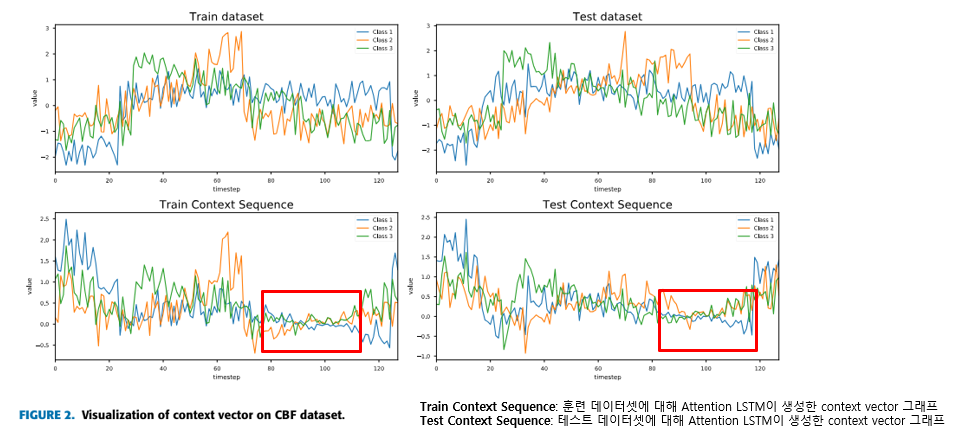
모델이 어느 부분을 "주의"하고 있는지, 즉 중요하다고 판단하고 있는지를 보여줍니다
2. Model
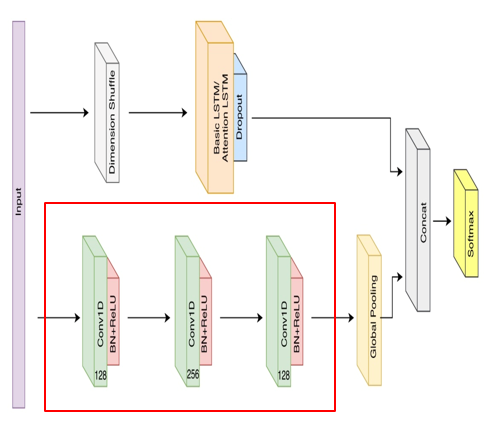
LSTM-FCN Network Architecture
LSTM과 Temporal Convolutional Network를 결합하여 시계열 분류에 활용 가능하게 한 구조
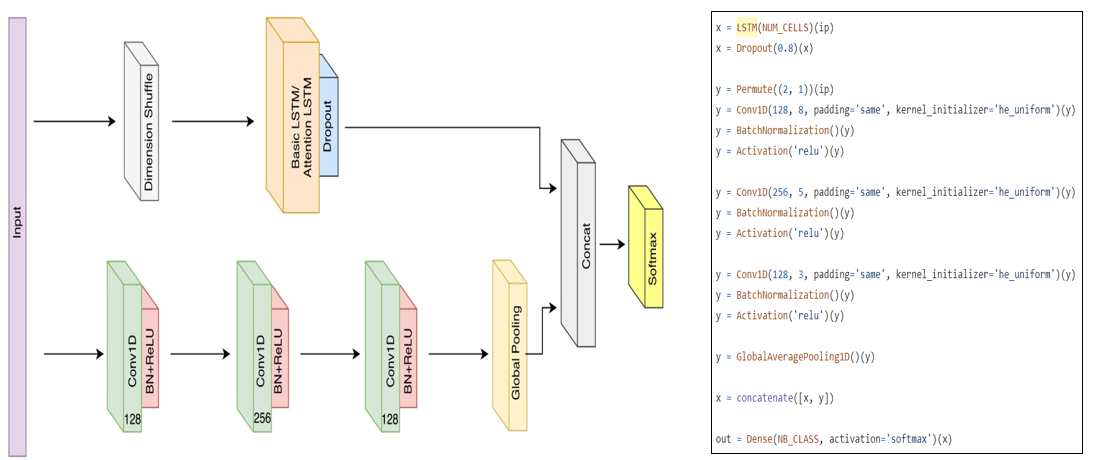
Network Input
: 길이가 N인 단변량(univariate) 시계열 데이터 입력
Dimension Shuffle
Ex) 85개의 UCR 데이터 세트 LSTM-FCN 모델 훈련: 100시간 이상 소요
Dimension shuffle 사용해 훈련: 18시간 소요(단일 GTX 1080 Ti GPU)
--> N개의 변수를 한 번의 시간 단계로 처리하기 때문에 프로세스가 훨씬 빠릅니다.
Refinement of Models
초기 모델을 학습한 후, 반복적으로 가중치와 하이퍼파라미터를 조정하여 모델 성능을 향상시키는 방법
1) 초기 학습: 최적 하이퍼파라미터 선택 후 초기 데이터셋으로 모델 훈련
2) Refinement Algorithm :
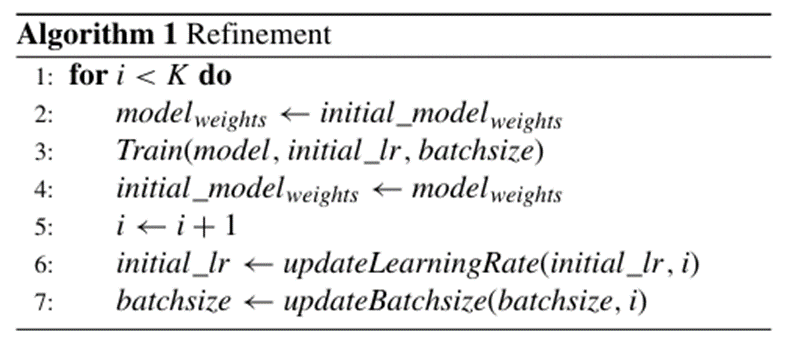
--> 정밀한 조정으로 초기 학습에서 도달한 local minima를 벗어나 더 나은 minima에 도달 가능
( 학습률 감소:더 작은 폭으로 가중치를 조정함/배치 크기 감소: 더 작은 데이터 샘플을 사용하여 가중치를 업데이트 하게됨)
2-1. Performance Evaluation
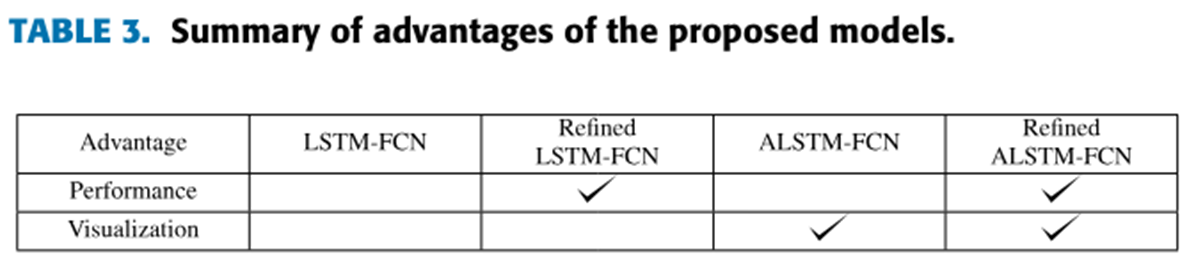
Refinement algorithm
Refinement 적용 후 클래스 별 평균 에러율(MPCE)가 각각 감소 (Refined LSTM-FCN :0.0035, Refined ALSTM-FCN: 0.0007)
3. Experimental Results
85개의 UCR 시계열 데이터셋에서 제안된 모델 성능 테스트
Refinement algorithm 적용 전/후의 LSTM-FCN/ALSTM-FCN 각각 테스트
à ALSTM-FCN, LSTM-FCN은 최소 43개 최대69개의 데이터셋에서 SOTA 모델보다 성능이 뛰어남.
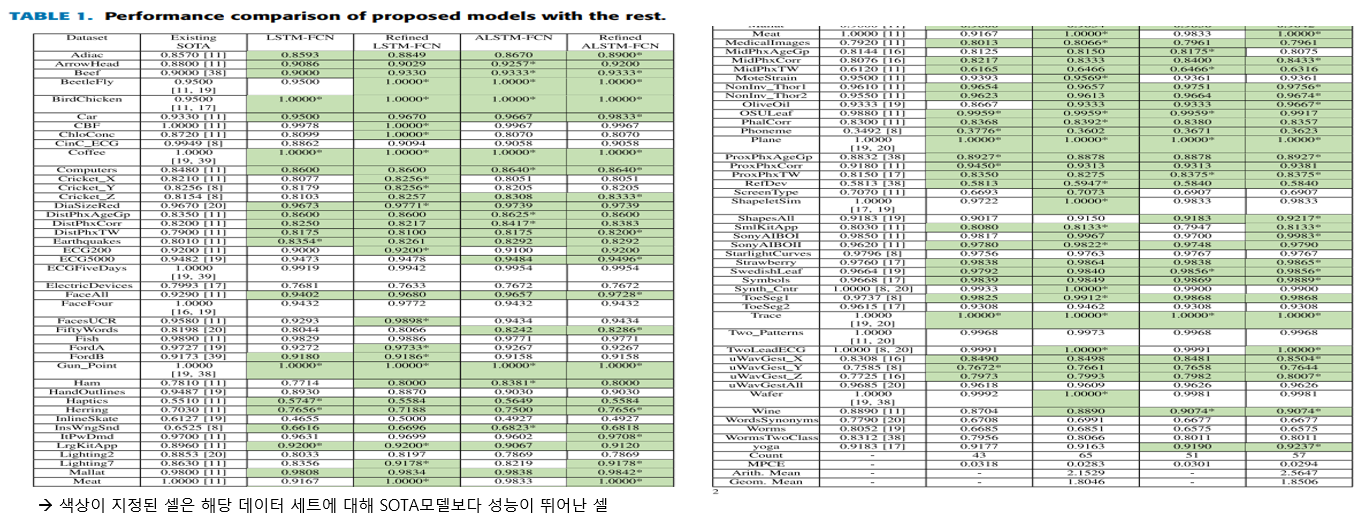
+ 논문과 내 목적과의 연관성 찾기💫
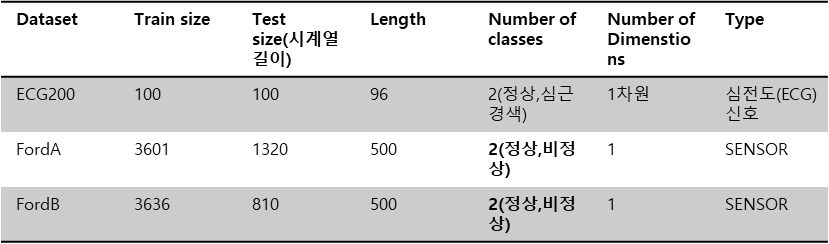
85개의 UCR 시계열 데이터셋 중 내 데이와 관련 데이터셋
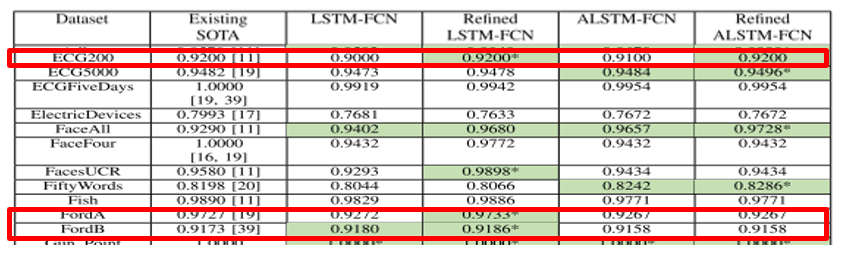
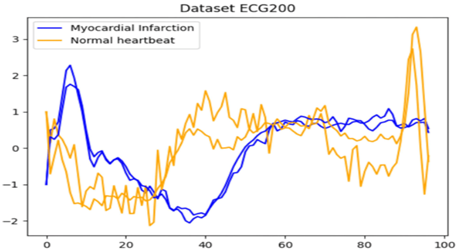
2. FordA, FordB
제안된 모델의 산술 평균 순위 (CD 다이어그램)
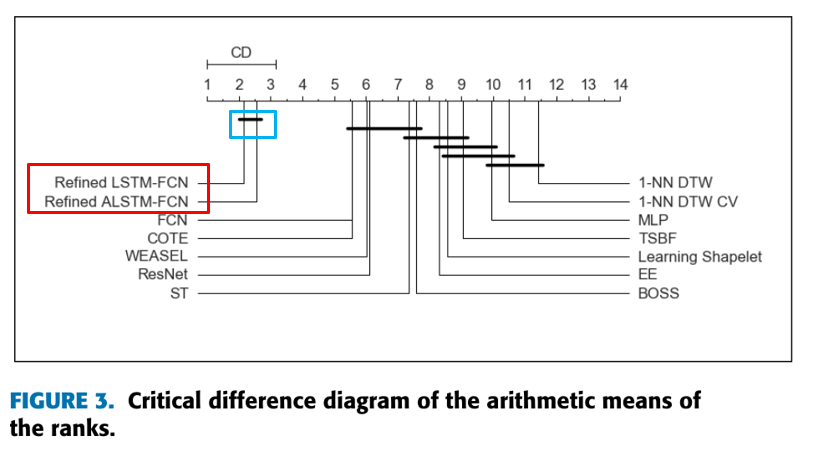
: 여러 데이터셋에서 각 모델의 순위 평균을 계산하여 성능 비교
--> 모델 간의 성능 차이가 통계적으로 유의미한지 여부를 나타냅니다.
Wilcoxon Signed-Rank Test
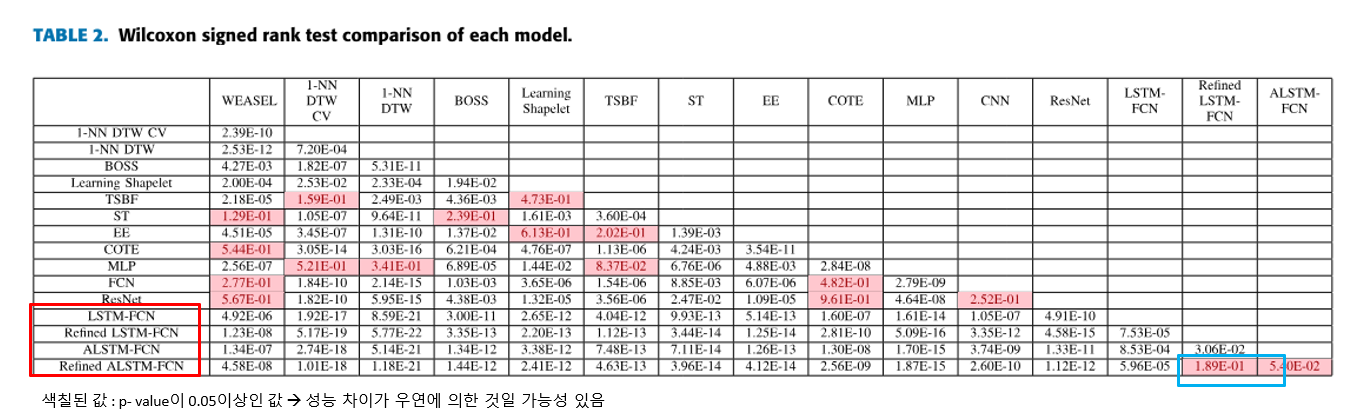
4. Conclusion
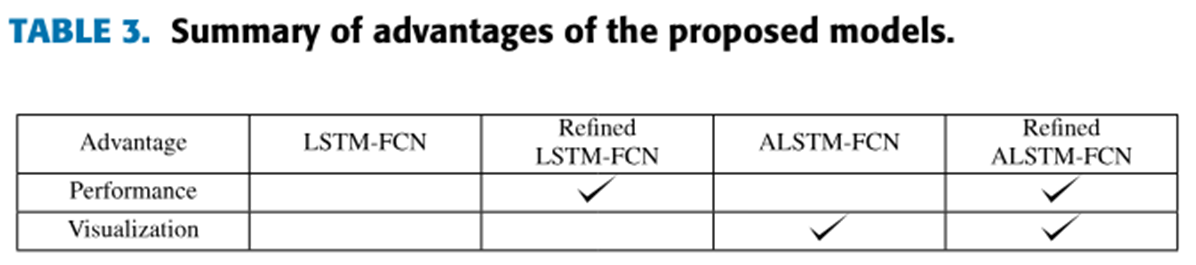
LSTM-FCN / ALSTM-FCN
(End to end: 입력(input)에서 출력(output)까지 파이프라인 네트워크 없이 신경망으로 한 번에 처리)
1. Temporal Convolutions (시계열 합성곱)
2. Recurrent Neural Networks (순환 신경망, RNNs)
3. Long Short-Term Memory RNNs (LSTM RNNs)
4. Attention Mechanism (주의 메커니즘)
요약:이 논문은 FCN의 성능을 향상시키기 위해 Temporal Convolution, LSTM RNN, Attention Mechanism을 결합한 모델을 제안합니다. 이 모델들은 시계열 데이터의 특징을 효과적으로 추출하고, 장기 종속성을 학습하며, 중요한 입력 부분에 집중하는 능력을 갖추고 있습니다.이를 통해 제안된 모델들은 기존의 복잡한 전처리 과정 없이도 뛰어난 성능을 발휘하며, 다양한 벤치마크 데이터셋에서 우수한 결과를 제공합니다. |
time series classification의 개념을 대략적으로 이해할 수 있도록 도와준 논문이었다.

