하이퍼파라미터 튜닝을 하면서 여러 방법들을 공부해보고 사용해보고 코드로 구현해볼 수 있는 시간이었다. 너무 다방면하게 하이퍼파라미터 튜닝 test에 집중하고 최적의 결과를 찾다보니 중간 기록과 정리는 조금 미흡하지만, 다음엔 더 잘하면 되니까!! 🤣🤗
하이퍼파라미터 튜닝
하이퍼파라미터 튜닝은 머신 러닝 모델을 학습할 때 사용되는 하이퍼파라미터들을 최적화하는 과정을 말한다. 하이퍼파라미터는 모델의 구조나 학습 과정에 영향을 주는 파라미터로, 보통 사용자가 직접 지정해야 하는 값들이다.
일반적으로 학습률, 배치 크기, 에포크 수, 가중치 초기화 방법, L1 또는 L2 규제의 강도, 드롭아웃 확률 등이 하이퍼파라미터에 해당한다. 이러한 하이퍼파라미터들은 모델의 학습에 직접적인 영향을 미치며, 적절한 값을 찾는 것이 모델의 성능과 일반화 능력에 매우 중요하다.
목표는 가장 우수한 성능을 내는 하이퍼파라미터 조합을 찾는 것이다. 하지만 이 과정은 많은 시간과 계산 리소스를 필요로 하기 때문에, Grid Search, Random Search, Bayesian Optimization, 그리드 기반 탐색 등과 같은 다양한 튜닝 기법이 사용되기도하는데 , 이 방법들을 나중에 알게되어서 다음 경진대회에 꼭 써봐야겠다.
Learning Rate (학습률)
학습률(Learning Rate): 학습률은 모델이 각 학습 단계에서 가중치를 얼마나 갱신할지를 결정하는 파라미터이다. 너무 작은 학습률은 학습 속도를 느리게 할 수 있고, 너무 큰 학습률은 수렴을 어렵게 할 수 있습니다. 따라서 적절한 학습률을 찾는 것이 중요하다.
적절한 학습률을 찾기위해 학습률 스케줄링을 사용하였다.
학습률 스케줄링은 학습 도중 학습률을 조정하는 기법으로, 학습이 진행됨에 따라 학습률을 점진적으로 줄이거나 조절하는 방법을 의미한다.
-초기 옵티마이저 설정과 스케줄링 설정 코드
# 옵티마이저 설정
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-3)import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
# 학습률 스케줄링 설정
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
#훈련에폭 안에
scheduler.step() # 매 epoch마다 학습률을 업데이트합니다.위의 코드처럼 PyTorch의 학습률 스케줄러 중 하나인 StepLR 클래스를 import해고, StepLR(optimizer, step_size=10, gamma=0.1)인 StepLR 클래스를 사용하여 학습률 스케줄링을 설정했다.위의 StepLR은 주어진 step_size인 10에포크마다 학습률을 gamma 비율인 0.1배씩 감소시킨다.이러한 스케줄링을 통해 학습이 진행되면서 학습률이 점진적으로 줄어들어 더욱 안정적으로 모델을 학습할 수 있었다.
Early Stopping (조기 종료)
Early Stopping은 모델의 성능이 더 이상 개선되지 않을 때 학습을 조기 종료하는 기법이다.
설정된 patience만큼의 epoch 동안 개선이 없을 경우 학습을 조기 종료하고 최상의 가중치를 저장한다.
from early_stopping import EarlyStopping
# Early Stopping 객체 생성
# 검증 손실이 5번 연속으로 개선되지 않으면 학습이 조기 종료 되도록 설정
#verbose: True로 설정하면 개선이 없을 때마다 로그를 출력하며, False로 설정하면 로그를 출력하지 않습니다.
early_stopping = EarlyStopping(patience=5, verbose=True) # Early Stopping 체크
early_stopping(val_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break patience=5로 설정하면 검증 손실이 5번 연속으로 개선되지 않으면 학습이 조기 종료되도록 설정함.
verbose: True로 설정하면 개선이 없을 때마다 로그를 출력하며, False로 설정하면 로그를 출력하지 않는다.
Regularization (정규화) 기법
정규화는 머신 러닝 모델의 학습 과정에서 과적합(overfitting)을 방지하고 일반화 능력을 향상시키는데 사용되는 기법들을 의미한다. 과적합은 모델이 학습 데이터에 과도하게 적합하여 새로운 데이터에 대해 예측 성능이 떨어지는 현상을 말한다. 정규화 기법은 이러한 문제를 완화하고 모델의 성능을 일반화시키는 데에 도움을 준다.
1.Dropout
Dropout은 학습 과정에서 랜덤하게 일부 뉴런을 비활성화하는 기법이다. 학습 단계에서 일부 뉴런이 무작위로 제거되기 때문에 모델은 특정 뉴런에 지나치게 의존하지 않게 되고, 더 일반화된 모델을 만들 수 있다.
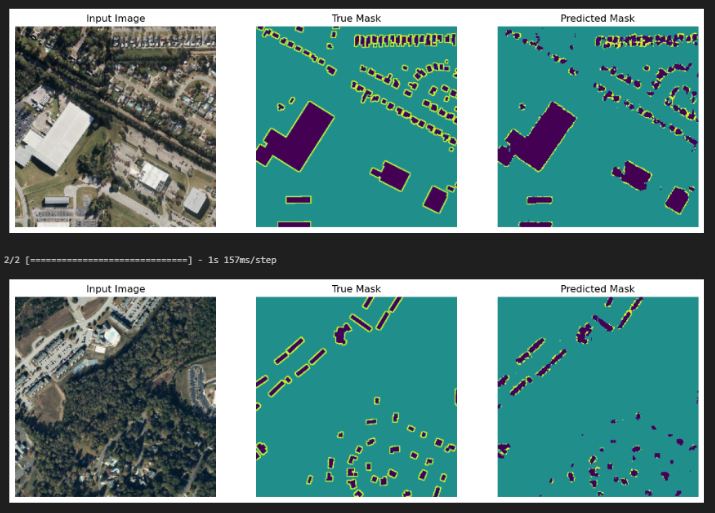
비교시 dropout이 성능을 향상시키지 못하고 오히려 성능이 저하됨을 확인했다.
Dropout은 데이터 양이 많을 때 특히 효과적이지만 훈련데이터는 7000장이라 Dropout이 모델의 성능 향상에 제한적일 수 있다고 한다. 이 경우 데이터 증강 기법을 활용하여 데이터를 다양하게 만들거나 다른 방법으로 데이터셋을 보강할 필요가 있다.
다음에 추가적인 실험을 수행해서 모델 성능을 향상시키기 위해 다양한 시도를 해봐야 할 것 같다.
| dropout | leader board score |
| 사용안함 | 0.2675622268 |
| 0.1 | 0.1744884041 |
| 0.2 | 0.2292057794 |
*여기서 leader board score 파라미터를 비교하기위한 지표일뿐 최종 모델 성능과는 관련없음.
2.L2규제
L2 규제는 가중치(weight)의 크기를 제한하여 모델의 복잡성을 감소시키는 정규화(regularization) 기법 중 하나이다. 가중치의 크기가 커지면 모델이 학습 데이터에 과적합(overfitting)될 가능성이 높아지며, 새로운 데이터에 대한 일반화 능력이 저하될 수 있다.
L2 규제는 손실 함수에 가중치의 제곱항을 추가하여 적용된다. 따라서 L2 규제를 사용하는 경우, 손실 함수는 가중치의 제곱항을 포함하게 된다.
L2 규제를 적용한 손실 함수 = 기존 손실 함수 + λ * (가중치의 제곱항)
여기서 λ는 L2 규제의 강도를 조절하는 하이퍼파라미터(weight_decay)입니다. weight_decay 값이 작을수록 L2 규제의 강도가 약화되며, 값이 커질수록 L2 규제의 강도가 강화됩니다.
-사용한 L2규제 코드
# 옵티마이저 설정
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-3)weight_decay=1e-3은 L2 규제의 강도가 상대적으로 강하게 적용되는 값이다. 즉, 가중치의 크기를 상대적으로 작게 유지하여 모델의 복잡성을 줄이고 일반화 능력을 향상시키려는 목적으로 사용하였다.
--------------------
Loss function
하이퍼파라미터 튜닝에서 loss function은 모델을 학습하는 동안 최적화해야 하는 목적 함수를 말한다. 모델이 학습 데이터와 실제 타겟(ground truth) 데이터 간의 차이를 측정하는 함수로, 이 차이를 최소화하는 방향으로 모델의 가중치를 조정한다.
손실 함수는 학습하는 동안 모델의 예측값과 실제 타겟값 사이의 오차를 계산하고, 이 오차를 최소화하기 위해 최적화 알고리즘을 사용하여 모델의 가중치를 업데이트한다. 즉, 모델이 얼마나 잘 예측하고 있는지를 평가하는 기준으로서 학습 과정에서 매우 중요한 역할이다.
(1) Binary Cross Entropy
Binary Cross Entropy Loss 은 이진 분류 문제에서 모델의 출력값과 실제 타겟값 사이의 차이를 측정하여 오차를 계산하는 손실 함수이다.
Binary Cross Entropy Loss의 계산 방법:
-모델의 출력값(예측 확률)을 이용하여 예측된 클래스에 대한 확률값과 반대 클래스에 대한 확률값을 구한다.
-실제 타겟값과 예측된 확률값 사이의 오차를 계산한다.
-오차를 최소화하기 위해 모델의 가중치를 조정하는 학습 과정을 진행한다.
*모델의 가중치는 학습과정에서 손실 함수의 값을 최소화하는 방향으로 조정됨.
*모델이 입력 데이터에대한 예측값을 출력하면 손실함수를 사용하여 예측값과 실제값에 대한 오차를 계산하고 , 손실함수의 값을 최소화하기 위해 오차를 모델의 가중치에 역전파하여 가중치를 조정한다. 역전파는 미분을 이용하여 손실 함수의 값이 최소화되는 방향으로 가중치를 갱신하는 과정이다. 이후 가중치를 업데이트하는 최적화 알고리즘(Adam 사용함)을 사용하여 (학습률과 같은 하이퍼파라미터를 사용하여) 가중치를 조정한다.이 과정을 반복하여 모델의 가중치를 업데이트하고 손실함수를 최소화 하는 방향으로 모델을 학습시키게 된다.
# loss function과 optimizer 정의
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-3)
torch.nn.BCEWithLogitsLoss()는 이진 분류(Binary Classification) 문제를 위한 손실 함수로서, 이진 교차 엔트로피 손실(Binary Cross Entropy Loss)의 변형이다. 이 손실 함수는 이진 분류 문제에서 모델의 출력값과 실제 타겟값 사이의 차이를 측정하여 오차를 계산합니다.
이 함수는 신경망의 출력값을 입력으로 받아서 소프트맥스(softmax)나 시그모이드(sigmoid) 함수를 적용하지 않아도 된다. 즉, 모델의 출력값이 로짓(logits) 형태인 경우에 사용할 수 있다. 로짓은 일반적으로 시그모이드 함수를 거친 값이 아닌, 모델의 선형 출력값을 의미한다.
torch.nn.BCEWithLogitsLoss()의 계산 방법:
-모델의 출력값과 실제 타겟값 사이의 이진 교차 엔트로피 손실을 계산한다.
-이 손실 값은 모델의 출력값에 시그모이드 함수를 적용한 결과에 대해 계산된 것과 동일하다.
(2)FocalDiceLoss
FocalDiceLoss는 Focal Loss와 Dice Loss를 결합하여 사용하는 손실 함수이다. 이 손실 함수는 주로 이미지 분할 (Image Segmentation) 작업에 적용되며, 모델이 분할된 결과를 더 정확하게 예측하도록 돕는데 목적이 있다.
Focal Loss: Focal Loss는 불균형한 데이터셋에서 발생하는 클래스 불균형 문제를 해결하기 위해 제안된 손실 함수이다. 일반적인 교차 엔트로피 손실(Cross Entropy Loss)는 클래스 간의 불균형이 심할 경우 모델이 예측을 잘 하지 못할 수 있다. Focal Loss는 클래스 간의 불균형을 줄이기 위해 각 샘플에 가중치를 부여하여 학습을 진행한다. gamma 매개변수는 가중치를 조절하는 역할을 한다. gamma 값이 클수록 모델이 잘못 예측한 샘플에 더 큰 페널티를 부여하게 된다.
Dice Loss: Dice Loss는 분할된 결과의 유사도를 측정하는 손실 함수로서, IoU(Intersection over Union) 또는 Dice Score라고도 불린다. Dice Loss는 모델이 분할 결과를 실제 타겟과 얼마나 잘 일치하는지를 측정하여 최적화한다. Dice Score가 1에 가까울수록 모델의 예측이 정확하다고 볼 수 있다.
class FocalDiceLoss(nn.Module):
def __init__(self, gamma=2, smooth=1e-6):
super(FocalDiceLoss, self).__init__()
self.gamma = gamma
self.smooth = smooth
def forward(self, inputs, targets):
# Focal Loss 계산
inputs_prob = torch.sigmoid(inputs)
focal_loss = -targets * (1 - inputs_prob) ** self.gamma * torch.log(inputs_prob + self.smooth) \
- (1 - targets) * inputs_prob ** self.gamma * torch.log(1 - inputs_prob + self.smooth)
focal_loss = focal_loss.mean()
# Dice Loss 계산
dice_target = targets
dice_output = inputs_prob
intersection = (dice_output * dice_target).sum()
union = dice_output.sum() + dice_target.sum()
dice_loss = 1 - (2.0 * intersection + self.smooth) / (union + self.smooth)
# Focal Loss와 Dice Loss를 더해서 총 손실을 계산
total_loss = focal_loss + dice_loss
return total_loss
위의 손실 함수에서는 Focal Loss와 Dice Loss를 결합하여 사용했다. 먼저, 입력값을 시그모이드 함수를 통해 확률값으로 변환한다. 이후 Focal Loss와 Dice Loss를 계산하여 각각 focal_loss와 dice_loss에 저장한다. 마지막으로 focal_loss와 dice_loss를 더해서 최종 손실 함수 total_loss를 구한다. 이렇게 결합된 손실 함수를 사용하면 모델은 클래스 불균형 문제를 해결하면서 분할 결과를 정확하게 예측할 수 있도록 학습될 수 있다.



(3) Loss function comparison
이 위성 사진 데이터셋은 focaldiceloss가 모델 성능 개선에 더 효과적이었음을 확인했고 최종적으로 focal dice loss를 선택했다.
| loss function | leader board score |
| Binary Cross Entropy | 0.4151739052 |
| FocalDiceLoss | 0.5388942175 |
4.optimization algorithm
최적화 알고리즘(Optimization Algorithm)은 딥 러닝 모델의 가중치(파라미터)를 학습 과정에서 조정하여 손실 함수를 최소화하는 방법을 의미한다. 딥 러닝 모델은 입력과 출력 간의 관계를 나타내는 많은 가중치를 가지고 있으며, 이러한 가중치를 학습하여 입력과 출력 사이의 패턴을 인식하도록 합니다. 최적화 알고리즘은 이러한 가중치를 학습하는데 사용되며, 학습 과정에서 최적화 알고리즘은 가중치를 업데이트하면서 모델이 더 나은 성능을 발휘할 수 있도록 돕습니다.
# 옵티마이저 설정
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-3)(1) Adam optimization algorithm
Adam은 경사하강법(Gradient Descent) 기반의 최적화 알고리즘으로, 경사하강법의 한 변종으로서 일반적인 경사하강법보다 빠르게 수렴하는 특징이 있다.
Adam 특징:
- 모멘텀(Momentum) 기법: Adam은 모멘텀 기법을 사용하여 가중치 업데이트를 진행한다. 모멘텀은 이전에 업데이트된 가중치의 방향과 크기를 고려하여 현재 업데이트를 진행하는 방식으로, 더 빠르게 수렴하고 지역 최소값에서 빠져나오는 특징이 있다.
- RMSProp 기법: Adam은 RMSProp 기법을 사용하여 학습률을 조절한다. RMSProp은 기울기의 제곱값의 지수 평균을 사용하여 학습률을 조정하는 방법으로, 각 가중치에 다른 학습률을 적용하여 학습을 안정화시키는 효과가 있다.
'Machine Learning > ML Contest' 카테고리의 다른 글
| RSNA 2023 Abdominal Trauma Detection(1) -base line 입문 (0) | 2023.09.24 |
|---|---|
| 위성 이미지 건물 영역 분할 AI 경진대회 - (4) - 모델 구축 및 실험관리 (0) | 2023.08.04 |
| 위성 이미지 건물 영역 분할 AI 경진대회 - (2) - EDA & Preprocessing (0) | 2023.08.02 |
| 위성 이미지 건물 영역 분할 AI 경진대회 - (1) - intro (0) | 2023.08.01 |



